


The IT industry loves stacks. First there was the LAMP stack, then the Hadoop stack became popular. Over the past five years, something called the Modern Data Stack has taken root in our collective data psyche, and now there are whispers of something called the Compsable Data Stack. But is the stack concept still useful for big data and analytics?
IT stacks were born out of a desire to minimize the integration effort involved in assembling production systems, typically from open source components. You can download and hook elements of the original LAMP stack, including the operating system (Linux), web server (Apache), database (MySQL), and programming language (PHP, or Python or Perl). Working together to deliver web apps in 2005 without paying Accenture or another SI a 7-figure contract.
By 2010, the Hadoop era ushered in new practices in the stack. Originally built on a combination of a distributed file system (HDFS) and a computing framework (MapReduce), the Hadoop stack continued to grow and eventually became a collection of about 24 different projects (Hive, Spark, HBase, etc.) It has changed to etc. ).
Sounds great in theory, but the practicality of keeping Asparagus Chart up-to-date is limited by the likes of Hortonworks and Cloudera, not to mention maintaining compatibility across dozens of evolving open source projects. This has proven to be unbearable for many companies. The elephant and its accompanying building blocks tumbled down.
Rise of MDS
Although the Hadoop business model officially died in 2019, many Hadoop components (Spark, Presto, Kafka, Hive, and even HDFS) continue to live happy and productive lives elsewhere. By other places we mean the cloud, which brings us the Modern Data Stack (MDS for short).
MDS started taking root around the same time cloud giants started gobbling up big data workloads. Instead of trying to run their own integrated stacks of Hadoopery, public cloud vendors like AWS are using tools like Glue for ETL, RedShift for SQL data analysis, and Elastic MapReduce (EMR) for traditional Hadoop workloads. Provided shrink-wrapped data services to customers. Google Cloud had its own stack based on BigQuery, as did Snowflake, Microsoft, and eventually Databricks. There weren’t a lot of deployment options or adjustments to make, but it turned out to be a good thing as customer adoption skyrocketed.
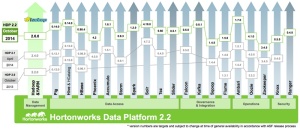
Hortonworks Asparagus Chart, circa 2014
The cloud is now an integral part of MDS. If you have MDS, it is assumed that you are running the components in a modern cloud manner. This means decoupling compute from storage and enabling infinite scalability through containers and serverless technologies and techniques. Therefore, the tools that surround and interoperate with the MDS must also conform to this new cloud era rather than the old days of on-premises compute and storage.
One proponent of MDS is Alation, a provider of data catalogs and governance tools. According to a 2023 blog post, MDS consists of data warehouses, ETL tools, data ingestion and integration services, reverse ETL, data orchestration, and business intelligence tools. “Modern data stacks are typically more scalable, flexible, and efficient than traditional data stacks,” he says in the Alation blog. “Modern data stacks rely on cloud computing, whereas traditional data stacks store data on servers rather than in the cloud.”
MongoDB is also a supporter of MDS. Like Alation, MongoDB is a term used to refer to a combination of pre-integrated software that runs on the cloud. It sees itself as several big data stacks, including MEAN, which includes MongoDB, Express, Angular, and Node. MERN: Includes MongoDB, Express, React.js, and Node. MEVN includes MongoDB, Express, Vue.js, and Node.
Stack begets stack
Time series database developer InfluxData is betting the future of InfluxDB on the FDAP stack. What is an FDAP stack? Glad you asked!
According to InfluxData (which coined the term), FDAP refers to a combination of several Apache Arrow projects, including Flight (a network protocol), DataFusion (a query engine), and Arrow itself (an in-memory columnar data format). Parquet (disk-based columnar data format). (stay tuned Data Nami Read the story of InfluxDB 3.0 built on FDAP here).
The Arrow ecosystem is currently growing rapidly, so it makes some sense for big data developers to build this as the core of a larger stack.
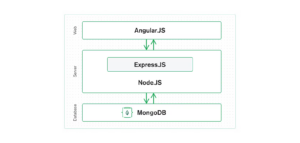
MEAN stack for MongoDB
Wes McKinney, the creator of Pandas and one of the creators of Arrow, recently co-authored a paper discussing these topics. The paper, titled “The Composable Data Management System Manifesto,” laments the rise of hundreds of data management systems, each building monolithic data silos that impede integration and progress. As you might have guessed, the solution is something called a “configurable data management system.”
“…[C]”Given the recent popularity of open source projects aimed at standardizing various aspects of the data stack, we advocate a paradigm shift in how data management systems are designed,” McKinney et al. write. “We believe that by breaking these down into modular stacks of reusable components, we can streamline development and provide a more consistent experience for our users.”
The Composable Data Stack, as McKinney calls it, is built around popular open source components such as Arrow, ORC, Parquet, Hudi, and Iceberg data formats. Column-oriented query processing for Velox and DuckDB. Apache Calcite and Orca for query optimizers. These include Ibis, Spark, Ray, and even the good old MapReduce execution framework.
“Despite sharing many of the same architectural decisions, data structures, and internal data processing techniques, today the degree of reuse between these systems is disturbingly limited,” the paper’s authors wrote. is writing. “We believe that by componentizing data management systems, we can accelerate the pace of innovation.”
Now we’re all MDS
However, not everyone agrees that an MDS stack is no longer necessary. According to Tristan Handy, co-founder and CEO of dbt Labs, the idea of a comprehensive big data stack is now redundant.
In a recent blog post, Handy shared his thoughts on why we live in a post-datastack world.
“When I was a consultant helping small businesses build analytics capabilities, I used only MDS tools. If the client wanted to use pre-cloud tools, I would rather not take on the project. Good for you,” he wrote. This term actually conveyed important information…now it has outlived its usefulness. ”
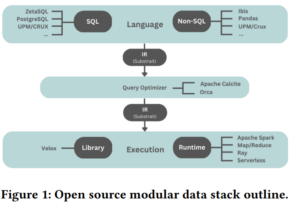
Composable Data Stack (courtesy of “Composable Data Management System Manifest”)
The data landscape in the field is changing dramatically, and most data products today are already built for the cloud, Handy writes. “Because they were built in the last decade, they either have cloud-first assumptions built in or have been redesigned as such,” he wrote.
To get his point across, Handy compared Looker and Tableau. His Looker, which Google acquired a few years ago, was hailed as a more modern set of analytical tools for working with cloud-based data warehouses such as Amazon Redshift. Acquired by Salesforce a few years ago, Tableau has been a dominant vendor since the pre-cloud era and was well-suited to working with on-premises data warehouses from the previous era.
While it’s true that Tableau didn’t have the same cloud capabilities as Looker in 2016, the team at Tableau did some hard engineering work to gain these capabilities and earn them a spot in the MDS club. .
Handy said there are many such examples. “I’ve talked to the founders of many of these companies, and ‘moving to the cloud’ almost always amounts to marching through a desert of misery for the company,” he wrote. . “But it’s such an existential thing that everyone does it anyway (or dies trying).”
Jump MDS Shark
Almost all big data tool vendors can now honestly say they are part of MDS, which in some ways has eroded MDS’ usefulness as a market differentiator. I got lost. This fact, combined with the deterioration of market conditions in 2023, caused MDS sales to decline.
“[C]Around 2021, MDS officially jumped the shark,” Handy wrote.
This is not to say that customers do not benefit from pre-integrated tools, i.e. datasheets. According to Handy, the willingness of buyers to build stacks of 8 to 12 vendors has decreased significantly.

Tristan Handy, founder and CEO of dbt Labs, plans to use the phrase “analytics stack” (Photo by MHamiltonVisuals)
“Enterprises today are much more likely to expect to purchase two to four products as the core of their analytics infrastructure,” Handy wrote. “This could further increase pressure for consolidation and encourage more M&A activity and competition across vendors.”
Behind all of this is the rise of AI and generative AI. MDS and GenAI are complementary, but asking potential buyers or investors to have two ideas in mind at the same time is going too far, Handy said.
“MDS was a large and important market trend,” he wrote. “But AI is bigger. Much bigger. And it’s difficult for data investors and data buyers to focus on too many trends at once.”
After all, using the MDS label is fighting the final war.
“Cloud has won. Every data company is now a cloud data company. Let’s move on,” he wrote. “What I talk about and think about in the future of the industry is analytics. It’s not the epitome of ‘analytics companies founded in the post-cloud era.'”
“Analysis stack” certainly has a nice ring to it.
Related products:
The time has come for an all-in-one data stack
Inside the modern data stack
In search of the latest data stack